
.jpg)

.jpg)




Welcome, humans.
People are using Super Mario to benchmark AI models now, and the results are surprising!

Anthropic's Claude 3.7 crushed the competition in a recent test by UC San Diego's Hao AI Lab using this GamingAgent, with Claude 3.5 taking second place. Meanwhile, Google's Gemini 1.5 Pro and OpenAI's GPT-4o struggled to keep pace.
What's interesting is that “reasoning” models like OpenAI's o1 actually performed worse, despite being stronger on most other benchmarks. Turns out timing is everything in Mario—even the most powerful AIs need quick reflexes to dodge those Goombas!
If this seems trivial to you, Andrej Karpathy thinks there’s an “evaluation crisis” in AI right now, so maybe AI gaming is actually the PERFECT benchmark for this “wtf is going on” moment…
And if we ARE using games to benchmark AI, it turns out someone made an AI that’s 60,500x smaller than DeepSeek v3 that can beat Pokémon Red. Your move, big AI labs.
Quick survey time: At The Neuron, we're always looking to improve your reading experience and would love your feedback on the length of the newsletter these days.
What do you think of The Neuron's length?
Your answer will help us deliver the purr-fect amount of AI news goodness to your inbox!
Here’s what you need to know about AI today:
- Wharton researchers found prompt engineering results vary by context.
- OpenAI planned tiered agents to replace professionals for $2K-$20K/month.
- Google added AI Mode to Search for premium subscribers.
- Amazon tested AI-dubbing on Prime Video content.

Science just proved why AI + human > AI alone…
Wharton researchers just released a fascinating study that questions everything we thought we knew about prompting AI. Spoiler alert: Being polite to Claude or ChatGPT doesn't always help—and sometimes, it actually hurts. We. Are. Shook!
The team, led by AI expert Ethan Mollick and colleagues at Wharton's Generative AI Labs, tested how different prompting approaches affect AI performance on a brutal PhD-level quiz.
They ran a whopping 19,800 tests per prompt across two models (GPT-4o and GPT-4o mini).
What they discovered might change how you interact with AI:
- Consistency is a major problem. The researchers asked the same questions 100 times and found models often give different answers to the same question.
- Formatting matters a ton. Telling the AI exactly how to structure its response consistently improved performance.
- Politeness is... complicated. Saying “please” helped the AI answer some questions but made it worse at others. Same for being commanding (“I order you to…”).
- Standards matter. If you need an AI to be right 100% of the time, you're in trouble.
- Both GPT-4o and GPT-4o mini performed just 5 and 4.5 percentage points better than random guessing on PhD-level questions when required to be perfect.

The study showed dramatic differences at the individual question level. For some questions, polite prompts boosted accuracy by over 60%, while for others, politeness tanked performance by similar margins. Context makes a big difference.
Why this matters: This has huge implications for how we use and evaluate AI tools. Companies relying on benchmarks alone might completely miss how inconsistent these models can be in real-world use.
Also, this inconsistency problem probably explains why genAI hasn’t been fully rolled out yet, despite the obvious gains it can unlock. Consistency is key.
For mission critical work, try asking the same question multiple times, then select the best answer.
Our take: This research suggests there's no “one-size-fits-all” approach to prompting. Those universal prompting tips you see online? They may work in some cases, but not others.
This matches our experience perfectly—it's why we avoid being too prescriptive with our own prompting advice. Instead, we embrace the human-in-the-loop approach: We save our best-performing prompts, but we're always ready to manually edit on the fly when results miss the mark.
That’s also why we think you, an actual human, should always place yourself as a final check between whatever your AI creates and whatever goes out into the world.

FROM OUR PARTNERS
Here’s one AI tool we use every week at The Neuron.
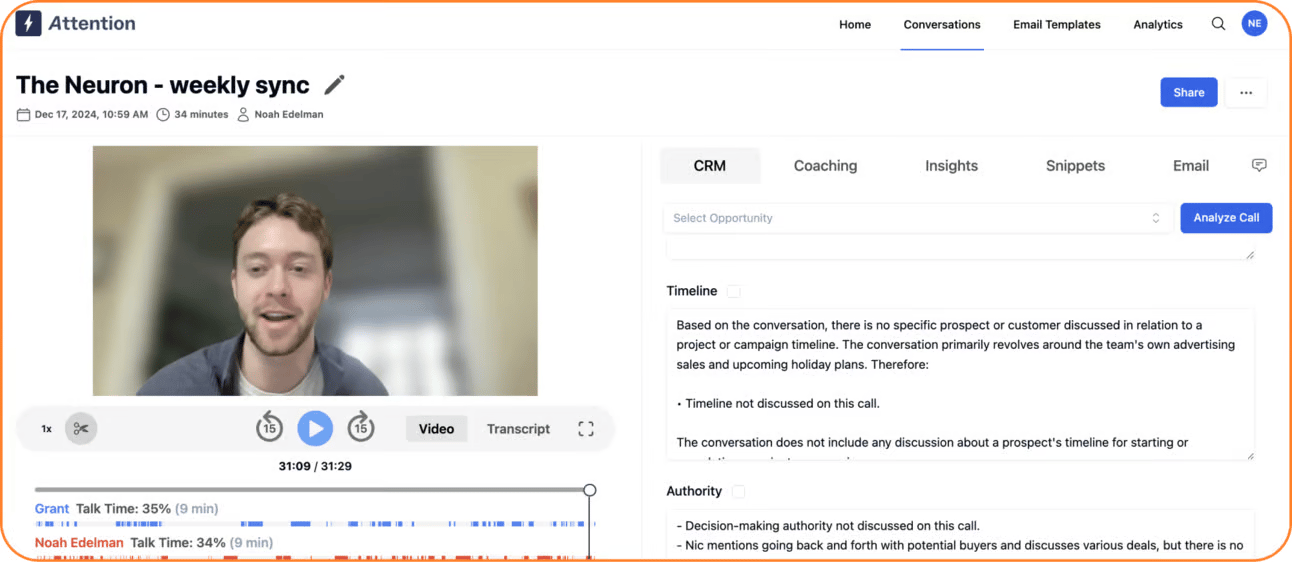
A little well-kept secret for companies crushing it with AI is that only a handful of AI tools are actually worth using.
That’s why we—Noah & Grant—use ChatGPT and Claude, along with a killer product called Attention.
Here’s how it works:
- We tell Attention exactly what to pay attention to in our meeting (goals, budget, etc).
- Attention listens in to our call.
- After, Attention outputs important insights, action items, and follow-up emails.
There’s plenty more features, too. So if you sell anything, literally drop what you’re doing and go book a demo with Attention ASAP.

What’s going on with OpenAI?
Since we covered Prompt Tips in our main story, let’s take a little time to cover what’s going on with OpenAI.
According to The Information, OpenAI is apparently planning to introduce tiered “AI agents” targeting different professional levels:
- $2K/month for knowledge workers.
- $10K/month for software development.
- $20K/month for PhD-level research.
The company expects these agents to eventually generate 20-25% of its revenue. While pricey, The Information thinks they could be a bargain compared to hiring a $200K developer or accelerating medical research.
Meanwhile, scientists are skeptical of AI’s ability to speed up their work. MIT's Sara Beery notes “most science isn't possible to do entirely virtually”, and that AI lacks context about researchers' goals and resources. And Sony researcher Lana Sinapayen says scientists want AI for tedious tasks like literature reviews, not creative work.
AI-generated “junk science” is already flooding academic search engines, potentially overwhelming the peer review process with low-quality or misleading studies.
So what happens when these new AI agents flood us with 10x more of it?

Treats To Try.

- Alibaba released QwQ-32B (featured above), an open-weights AI that you can run locally to solve your hardest problems by reasoning step-by-step through complex questions—try on the Qwen cloud here or try via this demo here.
- Hyperbolic is another AI cloud provider—for example, you can demo the new QwQ-32B AI model in its playground here.
- Gong analyzes your sales conversations to predict revenue outcomes and improve team performance (raised $250M).
- Depict creates Shopify collection grids that boost your store's conversion with auto-sorting and unique visuals.
- Lifestack schedules your tasks at optimal times by analyzing your health data, so you can work when you're energized and rest when you're not—free to try.
- Quadratic is a spreadsheet that chats with you, writes code, and connects to databases in your browser.
- ReframeAnything resizes any video for social platforms.
- Know Your Group creates landing pages for your WhatsApp/Telegram chat invite links so new members get to know your community before joining (free atm, but in beta)—also, it has the best launch video we’ve seen this week!
See our top 51 AI Tools for Business here!

Around the Horn.

- Here’s a surprisingly wholesome use of Wan 2.1, the newest (and newly popular) AI video generator—people are using it to animate their loved ones and pets.
- Google started to roll out a new AI Mode where you can ask complex, multi-part questions and follow-ups directly within Search, and new AI shopping tools to help you visualize clothing and beauty products.
- Amazon experimented with AI-dubbing for certain movies and TV shows on its Prime Video service.
- OpenAI prepared an upgrade that will let you edit your files directly through ChatGPT, with automatic app pairing and edit suggestions for apps like VSCode.
Thursday Trivia
One is real, and one is AI. Which is which? (vote below!)
A.

B.

Which is AI?
The answer is below, but place your vote to see how your guess compares to everyone else (no cheating now!)
Here are the results from last week’s trivia (A was AI):

11 humans, 4 robots—that’s a 73% win rate for the humans so far!
Here’s what you said:
- C.W. chose B: “A has extra data like time, progress bar, and stats.”
- A.P. chose A: “If I consider a model was trained to evaluate concepts and patterns for an 8-bit open world game I think it would include the health bar, coins, and weapons which are classic elements. The other game seems overly simplistic and atypical.”
- W.P. chose B: “Just looks like it is trying harder 😂”
A Cat's Commentary.

Trivia Answer: B is AI, and A is real…


.jpg)


